python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
서포트 벡터 머신(Support Vector Machine, SVM)은 클래스를 가장 잘 구분하는 최적의 결정 경계(초평면)를 찾는 강력한 분류 모델이다. 핵심 아이디어는 클래스 간 마진(margin)을 최대화하는 것이며, 경계에 가장 가까운 일부 데이터(서포트 벡터)만 사용하여 모델을 결정한다. SVM은 특히 고차원 데이터와 비선형 분류에서 우수한 성능을 보인다. 이 장에서는 선형 SVM부터 커널 트릭을 사용한 비선형 SVM까지 원리와 실무 활용법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 데이터 로드df = sns.load_dataset("penguins").dropna()# 특성과 타겟 준비X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]]y = df["species"]# 데이터 분할X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)print("데이터 크기:", X.shape)print("클래스:", y.unique())print("\n클래스 분포:")print(y.value_counts())
데이터 크기: (333, 4)
클래스: <StringArray>
['Adelie', 'Chinstrap', 'Gentoo']
Length: 3, dtype: str
클래스 분포:
species
Adelie 146
Gentoo 119
Chinstrap 68
Name: count, dtype: int64
25.1 SVM의 핵심 개념
SVM은 클래스 간의 마진을 최대화하는 최적의 결정 경계를 찾는다.
SVM의 핵심 아이디어
개념
설명
결정 경계 (Decision Boundary)
클래스를 구분하는 초평면
마진 (Margin)
결정 경계와 가장 가까운 데이터 사이의 거리
서포트 벡터 (Support Vectors)
마진 경계에 위치한 핵심 데이터
마진 최대화
일반화 성능 향상 목표
SVM의 장점
일반화 성능 우수 (마진 최대화)
고차원 데이터에 효과적
커널 트릭으로 비선형 문제 해결
소수의 서포트 벡터만 사용 (메모리 효율적)
이상치에 비교적 강건
SVM의 단점
대규모 데이터셋에서 학습 시간 오래 걸림 (O(n²~n³))
하이퍼파라미터 튜닝 필요 (C, gamma)
확률 출력 기본 제공 안 함
모델 해석 어려움
다중 클래스 분류는 내부적으로 여러 이진 분류기 조합
25.2 마진과 서포트 벡터
마진(Margin)
결정 경계와 가장 가까운 데이터 사이의 거리
마진이 클수록 일반화 성능 향상
SVM은 마진을 최대화하는 초평면 찾기
서포트 벡터(Support Vectors)
마진 경계에 위치한 핵심 데이터 포인트
결정 경계를 실제로 결정하는 데이터
전체 데이터의 일부만 사용 (효율적)
나머지 데이터는 모델에 영향 없음
SVM vs 로지스틱 회귀
구분
로지스틱 회귀
SVM
목적 함수
확률 최대화 (로그 우도)
마진 최대화
출력
확률 (0~1)
클래스 (확률은 옵션)
결정 경계
확률 기반
마진 기반
영향 데이터
모든 데이터
서포트 벡터만
해석
쉬움 (계수)
어려움
비선형
다항식 특성 추가
커널 트릭
대규모 데이터
적합
부적합
25.3 하드 마진 vs 소프트 마진
하드 마진 SVM
모든 데이터를 완벽히 분리
오분류 허용 안 함
현실 데이터에서는 거의 불가능
노이즈나 이상치에 매우 민감
소프트 마진 SVM
일부 오분류 허용
C 파라미터로 허용 정도 조절
실무에서 주로 사용
과적합 방지
C 파라미터의 의미
C 값
효과
마진
과적합 위험
C ↑ (큼)
오분류 엄격히 금지
좁음
높음
C = 1
균형 (기본값)
중간
중간
C ↓ (작음)
오분류 허용 많음
넓음
낮음 (과소적합 가능)
25.4 선형 SVM
선형 SVM은 선형 결정 경계로 클래스를 구분한다.
선형 SVM 특징
선형 초평면으로 분리
고차원 데이터에 효과적
계산 효율적
로지스틱 회귀의 강력한 대안
25.4.1 선형 SVM 실습
예제: 선형 SVM 학습
from sklearn.svm import SVCfrom sklearn.pipeline import Pipeline# 선형 SVM 파이프라인 (스케일링 필수)pipe_svm_linear = Pipeline([ ('scaler', StandardScaler()), ('model', SVC(kernel='linear', C=1.0, random_state=42))])# 학습pipe_svm_linear.fit(X_train, y_train)# 예측y_pred_linear = pipe_svm_linear.predict(X_test)# 평가accuracy_linear = accuracy_score(y_test, y_pred_linear)print("=== 선형 SVM 성능 ===")print(f"정확도: {accuracy_linear:.4f}")print(f"\n분류 리포트:")print(classification_report(y_test, y_pred_linear))# 서포트 벡터 개수svm_model = pipe_svm_linear.named_steps['model']print(f"\n서포트 벡터 개수: {svm_model.n_support_}")print(f"전체 학습 데이터 대비: {svm_model.n_support_.sum() /len(X_train) *100:.1f}%")
=== 선형 SVM 성능 ===
정확도: 1.0000
분류 리포트:
precision recall f1-score support
Adelie 1.00 1.00 1.00 29
Chinstrap 1.00 1.00 1.00 14
Gentoo 1.00 1.00 1.00 24
accuracy 1.00 67
macro avg 1.00 1.00 1.00 67
weighted avg 1.00 1.00 1.00 67
서포트 벡터 개수: [12 10 4]
전체 학습 데이터 대비: 9.8%
예제: C 값에 따른 성능 변화
# 다양한 C 값으로 실험C_values = [0.01, 0.1, 1.0, 10.0, 100.0]accuracies = []n_support_vectors = []for C in C_values: svm_temp = Pipeline([ ('scaler', StandardScaler()), ('model', SVC(kernel='linear', C=C, random_state=42)) ]) svm_temp.fit(X_train, y_train) acc = svm_temp.score(X_test, y_test) n_sv = svm_temp.named_steps['model'].n_support_.sum() accuracies.append(acc) n_support_vectors.append(n_sv)# 시각화fig, axes = plt.subplots(1, 2, figsize=(14, 5))# 정확도axes[0].semilogx(C_values, accuracies, marker='o', linewidth=2)axes[0].set_xlabel('C (Regularization)')axes[0].set_ylabel('Accuracy')axes[0].set_title('Linear SVM: C vs Accuracy')axes[0].grid(True, alpha=0.3)# 서포트 벡터 수axes[1].semilogx(C_values, n_support_vectors, marker='o', linewidth=2, color='orange')axes[1].set_xlabel('C (Regularization)')axes[1].set_ylabel('Number of Support Vectors')axes[1].set_title('Linear SVM: C vs Support Vectors')axes[1].grid(True, alpha=0.3)plt.tight_layout()plt.show()print("\n=== C 값별 결과 ===")for C, acc, n_sv inzip(C_values, accuracies, n_support_vectors):print(f"C={C:6.2f}: Accuracy={acc:.4f}, Support Vectors={n_sv}")
=== C 값별 결과 ===
C= 0.01: Accuracy=0.9254, Support Vectors=149
C= 0.10: Accuracy=1.0000, Support Vectors=61
C= 1.00: Accuracy=1.0000, Support Vectors=26
C= 10.00: Accuracy=1.0000, Support Vectors=18
C=100.00: Accuracy=1.0000, Support Vectors=12
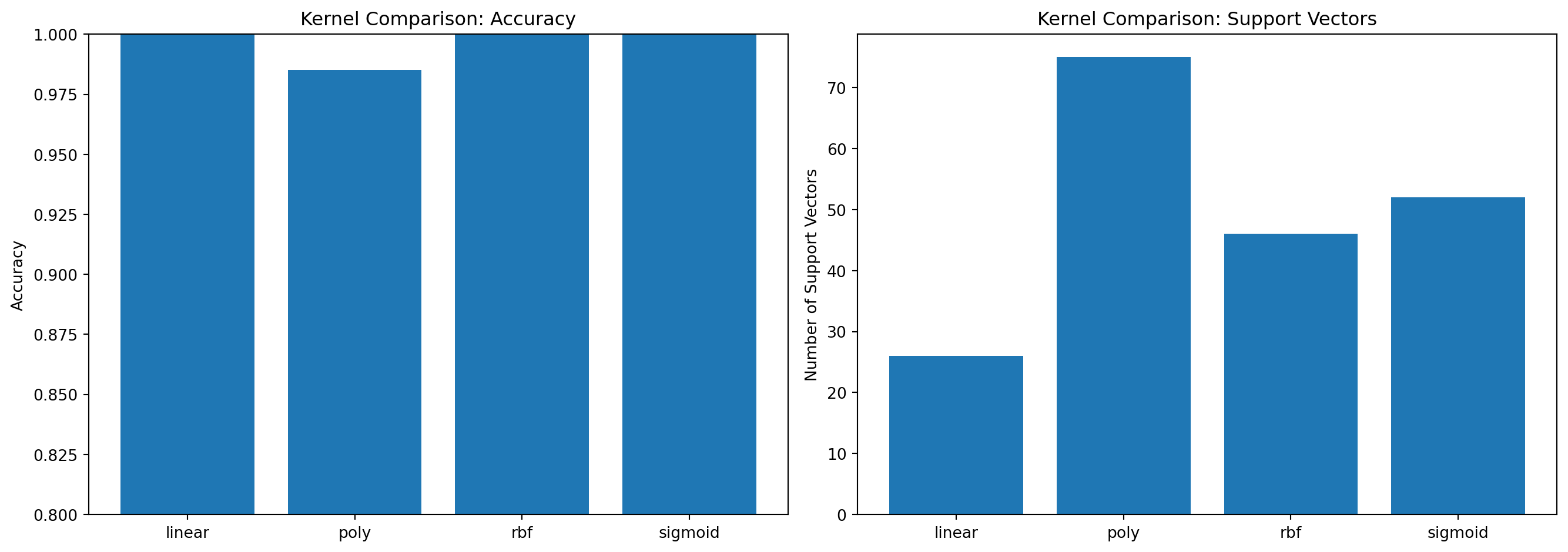
25.5 비선형 SVM과 커널 트릭
현실 데이터는 선형으로 분리되지 않는 경우가 많다. 커널 함수를 사용하면 비선형 경계를 만들 수 있다.
커널 트릭의 개념
원래 공간에서는 선형 분리 불가능
고차원 공간으로 매핑하면 선형 분리 가능
실제로 고차원 변환을 계산하지 않음
내적만 계산 (커널 함수) → 효율적
주요 커널 함수
커널
수식
특징
사용 상황
Linear
K(x, y) = x·y
선형 경계
선형 분리 가능
Polynomial
K(x, y) = (γx·y + r)ᵈ
d차 다항식 경계
중간 복잡도
RBF (Gaussian)
K(x, y) = exp(-γ‖x-y‖²)
무한 차원, 유연
일반적 상황 (가장 많이 사용)
Sigmoid
K(x, y) = tanh(γx·y + r)
신경망 유사
특수 상황
25.6 RBF 커널과 하이퍼파라미터
RBF(Radial Basis Function) 커널은 가장 널리 사용되는 비선형 커널이다.